Ollama 的本地部署性能
2024-12-18
engineer
Ollama
https://ollama.com/ 可以使用 PC 的 CPU 或 GPU 运行开源 LLM,有 Windows/Mac/Linux 版本,各家 LLM 也有针对 PC 的裁剪(量化)版本。3B 参数只需要 2GB 内存或显存。
性能表(单位 token/s)
| yi1.5-6b-Q4 | llama3.2-3b-Q4 | qwen2.5coder-14b-Q4 | qwen2.5-3b-Q4 | ||
|---|---|---|---|---|---|
| 模型大小 | 3.5GB | 2.0G | 9.0G | 1.9G | |
| 硬件 | Q1 | Q2(中文有bug) | |||
| NB-CPU(PS) | 11 | 17 | 17 | 3(内存不足) | 17 |
| NB-GPU(WSL) | 18 | 40 | 44 | 3(显存不足) | 44 |
| SVR-CPU | 8 | 13 | 11 | 4 |
硬件
Windows 笔记本(NB)
AMD Ryzen 7 4800H(16核 最高4.2GHz)
16GB 内存
Nvidia Geforce GTX 1650Ti(4GB)
512GB NVME SSD
Linux 服务器(SVR)
Intel Xeon Silver 4210R 2(10核20线程2,最高3.2GHz)
64 GB 内存
8TB SATA HDD
LLM 模型
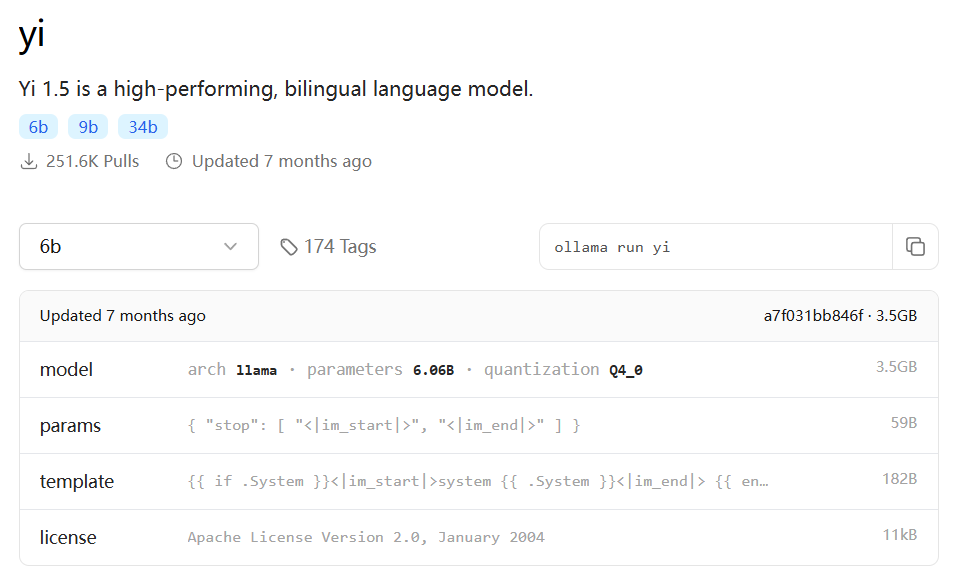
yi1.5-6B-Q4
测试问题:刘慈欣的三体里面,程心的性格是否帮助了地球文明
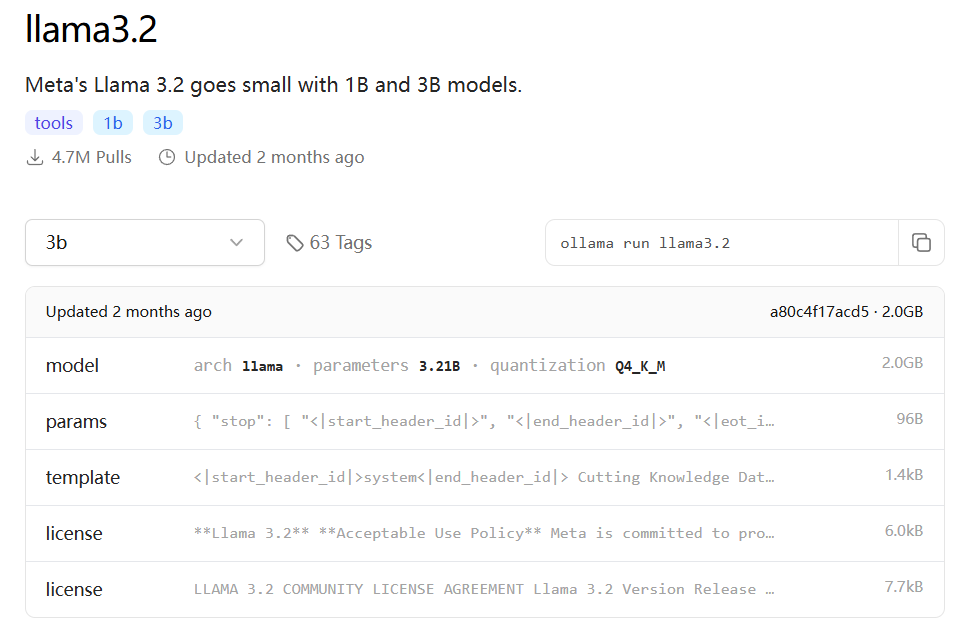
llama3.2-3B-Q4
测试问题:
- Q1: tell me the last 20 presidents of US and Chinese chairmen at same history age respectively
- Q2: 刘慈欣的三体里面,程心的性格是否帮助了地球文明
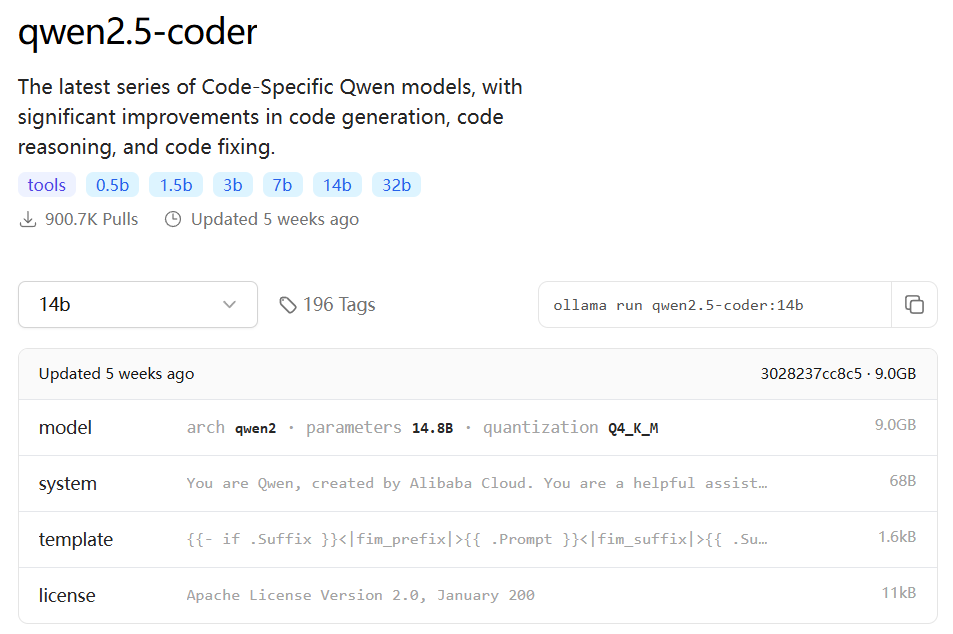
qwen2.5-coder-14B-Q4
测试问题:用python生成一段代码,要求:从excel文件中获取A列数据,在最后一行求和;获取B列数据在最后一行计算中位 数;获取C列数据获取标准差。A b c三列均为数字
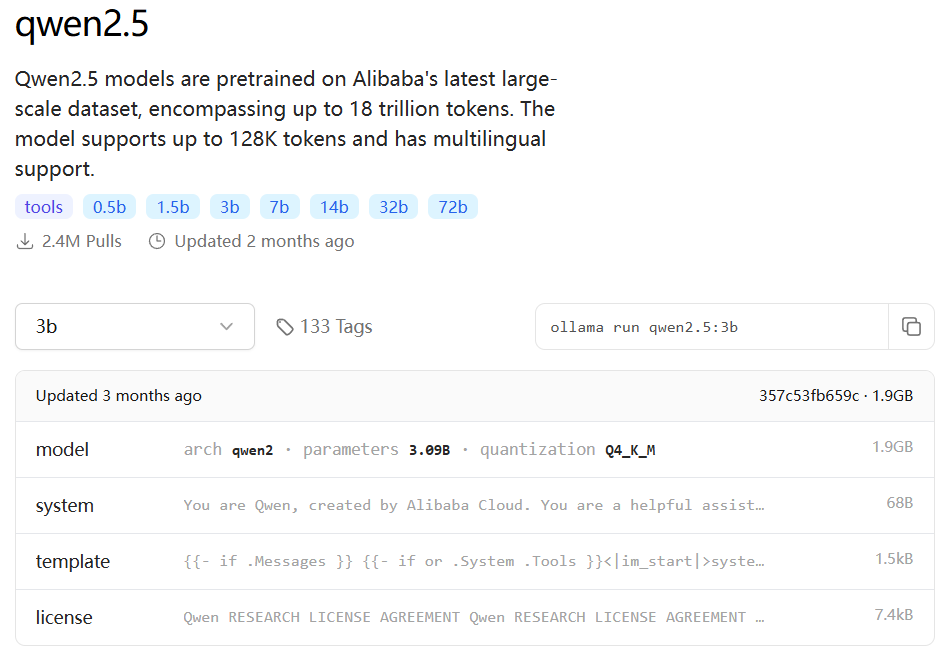
qwen2.5-3B-Q4
测试问题:刘慈欣的三体里面,程心的性格是否帮助了地球文明
其他
- 开启对话时,
ollama run qwen2.5-coder:14b --verbose中的--verbose可以在每次对话后查看性能表现 - 推理过程的性能随 context 加长而性能递减,因此需要及时用
/clear清理过去的对话记录 - 使用中发现双 CPU 服务器的 CPU 占用最高 50%,即推理任务实际只会使用一颗 CPU 的资源进行计算,或许和 ollama 只能使用一个 CPU 实例有关
- 模型首次载入需要的冷启动时间较长,测试中已排除该时间
- GPU 使用时,任务管理器中显示的占用率不高但很快到达 35-50W 的功率上限,需要用NVidia 显卡工具等查看实际占用率
- WSL 的 IO 损失在计算时间的占比下可以忽略不计
- Qwen 和 Llama 对 GPU 的利用效率更高。运行时 GPU 占用达到 70-80%,CPU 占用10-20%;而 Yi 运行时 CPU 占用 50%,GPU 占用 50%,可能和模型大小的参数量有关
- 在显存大小不足装下整个模型时(比如14B),推理性能被频繁的 CPU 调度制约,GPU 无法得到高效利用,效果还不如充足内存状态下的纯 CPU
Post TOC
Comments