之前遇到一个问题,在深圳的阿里云服务器向匈牙利和捷克的供应商接口请求数据,一次完整交互需要大概 10s,其中包含 4 次 POST 来回,以及写深圳数据库、深圳 OSS 存储等操作。而需要的指标是 90% 的完整交互在 3 秒内完成,差距非常大。过程如下:
sequenceDiagram
ECS-SZ ->>服务商: "POST-1, 300ms"
服务商 ->> ECS-SZ: "RESP-1, 300ms"
ECS-SZ ->>服务商: "POST-2, 300ms"
服务商 ->> ECS-SZ: "RESP-2, 300ms"
ECS-SZ ->>服务商: "POST-3, 300ms"
服务商 ->> ECS-SZ: "RESP-3, 300ms"
ECS-SZ ->>服务商: "POST-4, 300ms"
服务商 ->> ECS-SZ: "RESP-4, 300ms"
ECS-SZ ->>OSS-SZ: "store data"
ECS-SZ ->>RDS-SZ: "commit data"

不算服务器处理时间,这在路上就花了 2.4s,于是想到把发请求的服务器放到服务商附近,比如德国,使得来回传数据的时间压缩。
sequenceDiagram
ECS-SZ ->>ECS-DE: "POST-0, 300ms"
ECS-DE ->> ECS-SZ: "RESP-0, 300ms"
ECS-DE ->>服务商: "POST-1, 30ms"
服务商 ->> ECS-DE: "RESP-1, 30ms"
ECS-DE ->>服务商: "POST-2, 30ms"
服务商 ->> ECS-DE: "RESP-2, 30ms"
ECS-DE ->>服务商: "POST-3, 30ms"
服务商 ->> ECS-DE: "RESP-3, 30ms"
ECS-DE ->>服务商: "POST-4, 30ms"
服务商 ->> ECS-DE: "RESP-4, 30ms"
ECS-DE ->>OSS-SZ: "store data"
ECS-DE ->>RDS-SZ: "commit data"
ECS-DE ->> ECS-SZ: "DONE, 300ms"
ECS-SZ ->> ECS-DE: "ACK, 300ms"
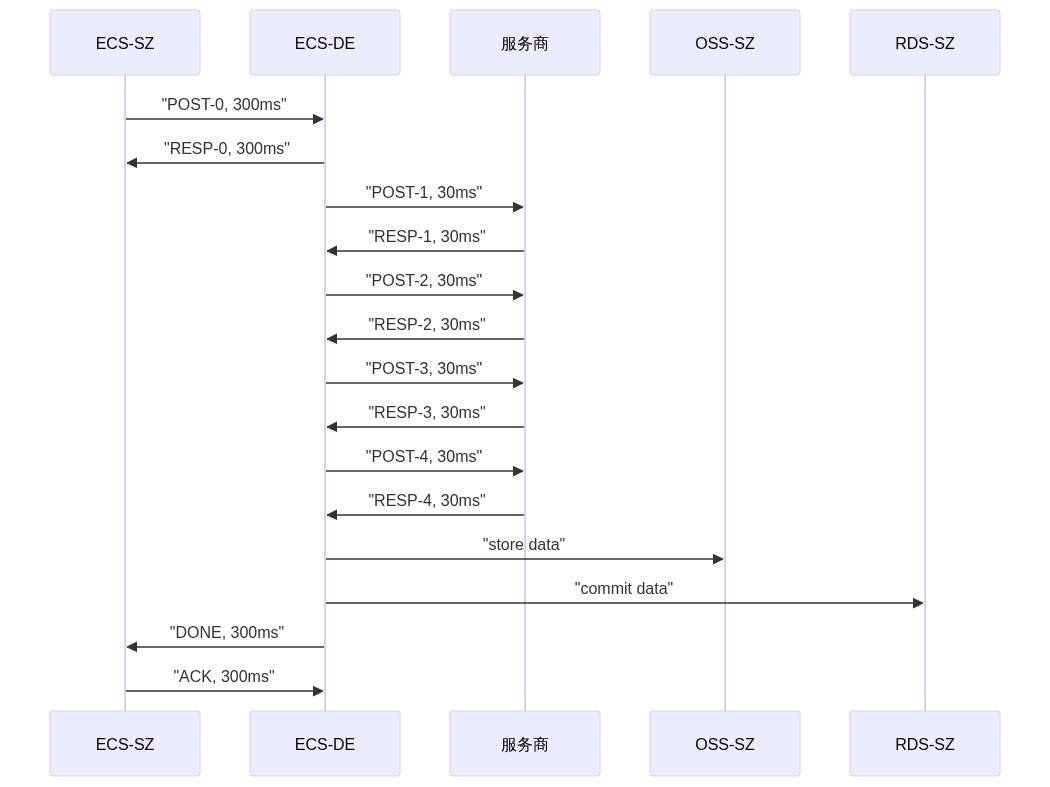
这样把路上的时间减少了大概 1-2s,由于略有成效,但发现最后 RDS 和 OSS 的写入非常差劲,因为这两步又成了跨国调用,导致时间更长了,再次优化,OSS 就地写在当地,等异步用资源的时候慢一点点倒无所谓。
sequenceDiagram
ECS-SZ ->>ECS-DE: "POST-0, 300ms"
ECS-DE ->> ECS-SZ: "RESP-0, 300ms"
ECS-DE ->>服务商: "POST-1, 30ms"
服务商 ->> ECS-DE: "RESP-1, 30ms"
ECS-DE ->>服务商: "POST-2, 30ms"
服务商 ->> ECS-DE: "RESP-2, 30ms"
ECS-DE ->>服务商: "POST-3, 30ms"
服务商 ->> ECS-DE: "RESP-3, 30ms"
ECS-DE ->>服务商: "POST-4, 30ms"
服务商 ->> ECS-DE: "RESP-4, 30ms"
ECS-DE ->>OSS-DE: "store data"
ECS-DE ->> ECS-SZ: "DONE, 300ms"
ECS-SZ ->> ECS-DE: "ACK, 300ms"
ECS-SZ ->>RDS-SZ: "commit data"
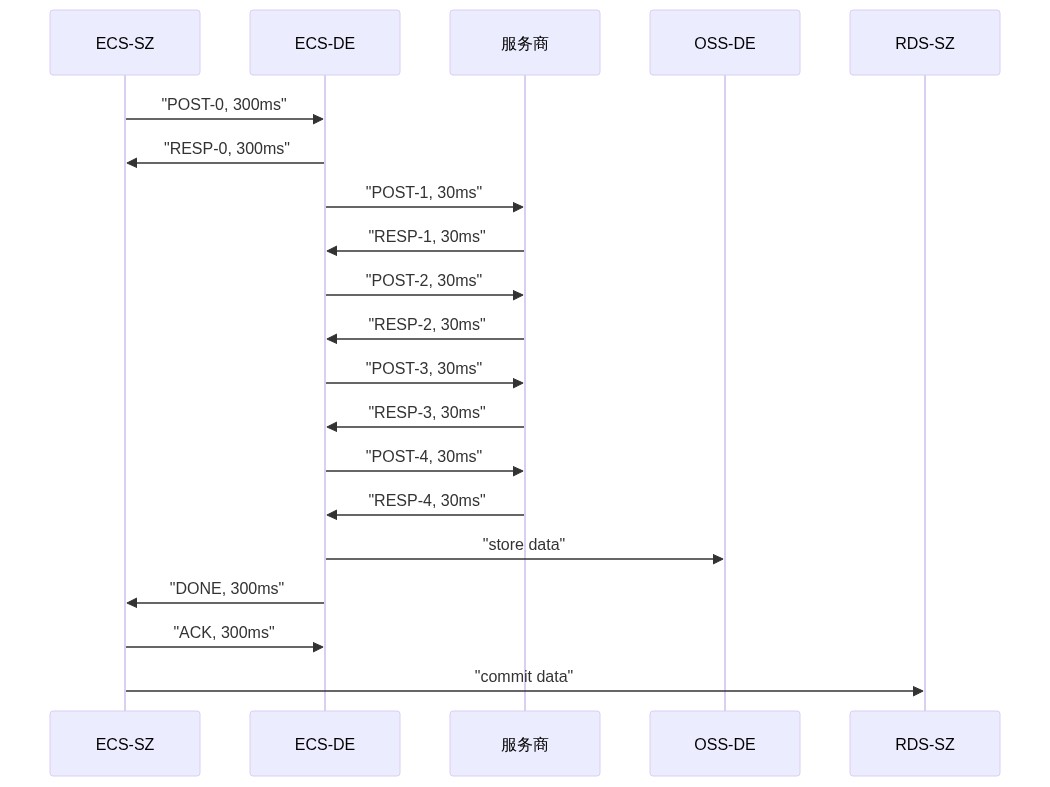
这样终于消停,整体下来把时间压缩到了 5s 左右。
结果没过几天,通信又出了问题,交互时间突然大幅延长到了 8-10s,整个链路检查下来,发现是 ECS-DE 和 ECS-SZ 之间的公网特别拥堵,阿里云对自身服务器之间的公网线路完全不优化,等着卖「全球加速」服务呢。不得已,重操旧业,用 traceroute 的方式确定物理路由节点,自己规划路线,从 163 光缆切到 CN2 上。
原路由的地理跳点真是要命:
graph LR
深圳 --> 广州
广州 --> San_Jose
San_Jose --> New_York
New_York --> 荷兰
荷兰 --> 法国
法国 --> 德国
选了两家跳板服务商:
- akkocloud,阿里云直连质量很棒,从广州出境走 CN2 直达法兰克福
- ucloud,深圳连香港,香港连德国
之前自己在 ucloud 用了很长时间,虽然没啥亮眼服务,而且时不时就优化线路发通知说「预计会有秒级网络抖动」,但好在质量还行,没死过机(在准备切掉阿里云德国的当天,那台服务器似乎有所察觉,在空载情况下宕机,头一次收到阿里云宕机警告...)。看在比起私人的 akkocloud 更不容易跑路的份上,就用了起来。
现在的路由变成:
sequenceDiagram
ECS-SZ ->>UC-HK: "POST-0, 30ms"
UC-HK ->> UC-DE: "POST-0, 200ms"
UC-DE ->> UC-HK: "RESP-0, 200ms"
UC-HK ->> ECS-SZ: "RESP-0, 30ms"
UC-DE ->>服务商: "POST-1, 30ms"
服务商 ->> UC-DE: "RESP-1, 30ms"
UC-DE ->>服务商: "POST-2, 30ms"
服务商 ->> UC-DE: "RESP-2, 30ms"
UC-DE ->>服务商: "POST-3, 30ms"
服务商 ->> UC-DE: "RESP-3, 30ms"
UC-DE ->>服务商: "POST-4, 30ms"
服务商 ->> UC-DE: "RESP-4, 30ms"
UC-DE ->>OSS-DE: "store data"
UC-DE ->> UC-HK: "DONE, 200ms"
UC-HK ->> ECS-SZ: "DONE, 30ms"
ECS-SZ ->> UC-HK: "ACK, 30ms"
UC-HK ->> UC-DE: "ACK, 200ms"
ECS-SZ ->>RDS-SZ: "commit data"
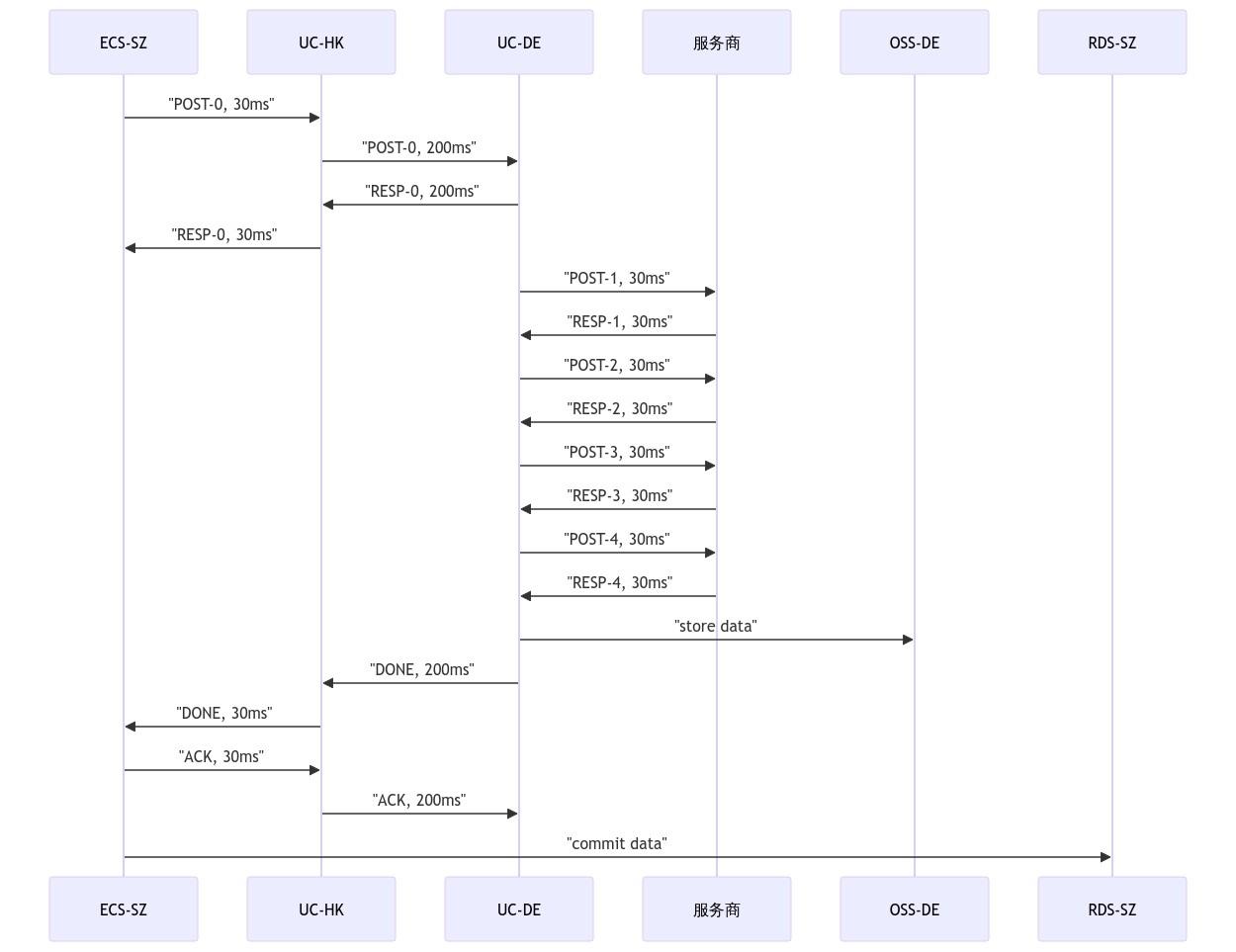
尝试过 ECS-SZ 直连 UC-DE,还是绕地球走法,放弃。虽然这样看起来流程冗长,但由于 UC-HK 和 UC-DE 之间的线路质量非常好,几乎没有丢包,因此重传的几率大大降低,节省了非常多的时间。
国内 163 线路 Ping 和 traceroute 延迟 250-300ms,但丢包率接近一半,因此整个交互远远不止延迟时间累加。而不丢包的国外 ISP 延迟稳定且不丢包——特别是长距离通信不丢包,对整个传输质量的提高帮助特别大。
下一步就是架一个负载均衡,把 akkocloud 直连的线路也加上,毕竟少一次中转就少一分出错的机会。